

Recent versions of Arroyo added support for HTTP sources, and treating individual lines of a response as streaming messages.
As a long-time user of Prometheus and Prometheus-style metric endpoints, this got me thinking: could you use Arroyo to process application metrics directly without using Prometheus at all? Now this is probably a bad idea (at least today!) but it turns out Arroyo can be useful for building alerting systems.
Table of Contents
- What are metrics?
- How alerts work in Prometheus
- Alerting with stream processing
- The Arroyo Pipeline
- Conclusion
- Full Query
What are metrics?
Software engineers and operators use metrics to provide insight into what our systems are doing. There are two main usage patterns:
- Exploratory analysis to understand some property of the system (aka why is this user complaining their application is slow?)
- Alerts to proactively indicate something is wrong or needs to be investigated (the server is on fire, we shouldn’t need a user to tell us that)

We should probably get an alert for this
We can think of these models as pull and push respectively.
Today Arroyo isn’t very good at pull use cases, because there is no support for ad-hoc querying.
But it actually makes a surprisingly good alert engine, despite having been designed as a data-oriented stream processor.
How alerts work in Prometheus
Prometheus is primarily a metrics database, responsible for ingesting metrics and making them available to query. Rather than having applications report metrics to it, Prometheus instead scrapes HTTP exposed by applications.
It implements alerting by allowing the user to configure “alerting rules” which are pre-configured queries that are executed at regular intervals.
For example, we could create a rule that triggers if average CPU usage has been above 90% for more than 1 minute:
- alert: HighCPU
expr: avg(irate(node_cpu_seconds_total{mode="idle"}[1m]) * 100) < 10
for: 1mThis approach can run into a number of issues at scale:
- With a lot of alerts, the query volume on prometheus can be substantial; users may have to reduce the frequency of alert checking to compensate (and thus increase the time to alert when something goes wrong)
- Alerts depend on Prometheus availability, which can be impacted by users running expensive queries or other issues
Alerting with stream processing
Stream processors like Arroyo invert this model: instead of storing all metrics in a database and periodically running alert queries against it, we continously run our queries on ingestion. This can be much more efficient, easier to scale, and more reliable.
However it only solves the alerting (and dashboarding) case—you still want Prometheus around for ad-hoc querying.
The Arroyo Pipeline
How can we use Arroyo to replace this metrics pipeline? There are number of possible ways to integrate Arroyo into your metrics system. For example, if your metrics data already flows over Kafka you could read it from that stream.
But I’m going to assume you don’t have any infrastructure aside from a service that exports prometheus metrics by hosting a /metrics endpoint.
Setting up our metrics endpoint
To follow along at home, you can use the Prometheus Node Exporter, which provides access to system metrics like CPU and Memory usage.
On MacOS, you can install it with Homebrew:
$ brew install node_exporter
$ brew services start node_exporterBy default the node exporter runs on port 9100. We can take a look at its output:
$ curl -s localhost:9100/metrics | grep cpu | head
# HELP node_cpu_seconds_total Seconds the CPUs spent in each mode.
# TYPE node_cpu_seconds_total counter
node_cpu_seconds_total{cpu="0",mode="idle"} 59524
node_cpu_seconds_total{cpu="0",mode="nice"} 0
node_cpu_seconds_total{cpu="0",mode="system"} 12839
node_cpu_seconds_total{cpu="0",mode="user"} 13590.08
node_cpu_seconds_total{cpu="1",mode="idle"} 63104.25
node_cpu_seconds_total{cpu="1",mode="nice"} 0
node_cpu_seconds_total{cpu="1",mode="system"} 9736.03
node_cpu_seconds_total{cpu="1",mode="user"} 13169.29Starting Arroyo
The easiest way to run Arroyo is in Docker. With Docker running, we can start a local Arroyo instance with
$ docker run -p 5115:5115 ghcr.io/arroyosystems/arroyo:latestThen we can load the web ui at http://localhost:5115, and click “Create pipeline” to start creating a new pipeline.
Parsing Prometheus metrics
Arroyo doesn’t ship with built-in support for Prometheus metrics, but that’s not a problem. We can use its powerful UDF (user-defined function) capabilities to implement our own parser in Rust.
The lines that we’re going to be parsing look like this:
node_cpu_seconds_total{cpu="1",mode="idle"} 63104.25We have a metric name (node_cpu_seconds_total), a series of label key/value pairs (cpu=1) and (mode=idle), and a value (63104.25).
We are going to parse those with two regexes: one that pulls out metric, labels, and value, and second that pulls out the individual key/value pairs.
Then we’ll rewrite the data as JSON, which allows us to use the data easily from SQL1.
The full UDF looks like this:
/*
[dependencies]
regex = "1.10.2"
serde_json = "1.0"
*/
fn parse_prom(s: String) -> Option<String> {
use regex::Regex;
use std::collections::HashMap;
// use OnceLock to prevent re-compilation of the regexes on every request
use std::sync::OnceLock;
static METRIC_REGEX: OnceLock<Regex> = OnceLock::new();
let metric_regex = METRIC_REGEX.get_or_init(|| {
Regex::new(r"(?P<metric_name>\w+)\{(?P<labels>[^}]+)\}\s+(?P<metric_value>[\d.]+)").unwrap()
});
static LABEL_REGEX: OnceLock<Regex> = OnceLock::new();
let label_regex = LABEL_REGEX.get_or_init(|| {
regex::Regex::new(r##"(?P<label>[^,]+)="(?P<value>[^"]+)""##).unwrap()
});
// pull out the metric name, labels, and value
let captures = metric_regex.captures(&s)?;
let name = captures.name("metric_name").unwrap().as_str();
let labels = captures.name("labels").unwrap().as_str();
let value = captures.name("metric_value").unwrap().as_str();
// parse out the label key-value pairs
let labels: std::collections::HashMap<String, String> = label_regex.captures_iter(&labels)
.map(|capture| (
capture.name("label").unwrap().as_str().to_string(),
capture.name("value").unwrap().as_str().to_string()
))
.collect();
// return the parsed result as JSON
Some(serde_json::json!({
"name": name,
"labels": labels,
"value": value
}).to_string())
}UDFs in Arroyo are normal Rust functions, with a few restrictions. They must take in and return a subset of types that correspond to SQL types. The inputs and return types can be wrapped in Option, which determines how they handle SQL nulls (see the full set of rules in the UDF docs). In this case we may encounter lines that are not valid prometheus metrics, so we return Option<String> in order to filter those out. 2
Given our example line:
node_cpu_seconds_total{cpu="1",mode="idle"} 63104.25calling parse_prom on it will return
Some( "{\"labels\":{\"cpu\":\"1\",\"mode\":\"idle\"},\"name\":\"node_cpu_seconds_total\",\"value\":\"63104.25\"}",)or looking at just the JSON:
{
"name": "node_cpu_seconds_total",
"value": "63104.25",
"labels": {
"cpu": "1",
"mode": "idle"
}
}Once we’ve developed our UDF, we can enter it into the Web UI. UDFs are managed in the udfs.rs tab of the pipeline creation page:
We can click “Check” to verify that the UDF is valid.
Setting up the polling source
Next we need to create a new source table that will poll our metrics endpoint. This will use the polling http connector, which is able to periodically poll an HTTP endpoint and emit the result as a data stream.
There are two ways to create sources and sinks in Arroyo: we can create reusable ones via the Web UI (using the connections tab), or directly in SQL as CREATE TABLE statements. Using the latter approach, our source could look like this:
create table metrics (
value TEXT,
parsed TEXT generated always as (parse_prom(value))
) WITH (
connector = 'polling_http',
-- set this to the correct address to reach your local node exporter;
-- if running Arroyo in Docker for Mac this should work
endpoint = 'http://host.docker.internal:9100/metrics',
format = 'raw_string',
framing = 'newline',
emit_behavior = 'changed',
poll_interval_ms = '1000'
);We start by defining the fields of the table. We’re using the raw_string format which expects a single field called value of type TEXT. Then we use Arroyo’s virtual field support to define the parsed field, which runs the input through our parse_prom function that we defined.
Then we define the connector configs; including the the endpoint that we should be polling (where our node exporter is running), the format, framing (which controls how the result of a request is split into lines; since Prometheus is line-oriented we use newline. The emit_behavior controls whether the source produces a new record on every call, or only when the data has changed, and the poll interval controls how often we poll the endpoint.
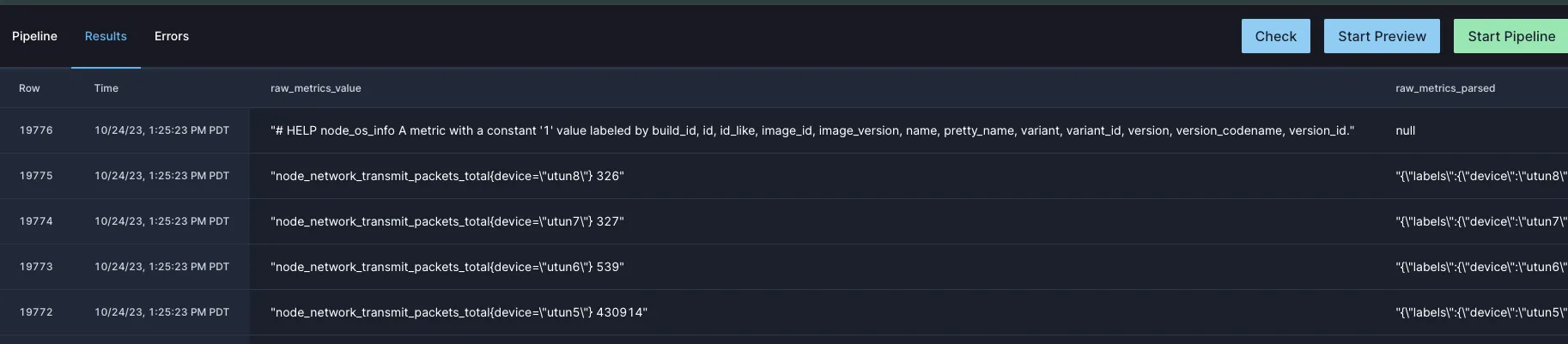
With our source set up, we can add a quick query to preview the data:
select * from metrics;and hit “Start Preview” to run a quick, preview pipeline.
After a few seconds that should start producing output like this:
Building our alert
Now that we have our data, we can start to build our actual alert. First we’ll set up a view over our data that contains just the CPU metrics in a convenient format:
CREATE VIEW cpu AS
SELECT
extract_json_string(parsed, '$.labels.cpu') AS cpu,
extract_json_string(parsed, '$.labels.mode') AS mode,
CAST(extract_json_string(parsed, '$.value') AS FLOAT) AS value
FROM metrics
WHERE extract_json_string(parsed, '$.name') = 'node_cpu_seconds_total';But we need one more thing before we can actually implement our alert. Prometheus reporters typically use counters to report how frequently some event occurs. A counter is an incrementing value which is periodically sampled by the prometheus scraper. In this case, our counter is node_cpu_seconds_total. To turn that into a rate, we need to compute how much the value has changed over an amount of time.
Arroyo doesn’t ship with an irate (instantaneous rate) aggregate functions, but we can use Arroyo’s support for user-defined aggregate functions (UDAFs) to implement our own:
fn irate(values: Vec<f32>) -> Option<f32> {
let start = values.first()?;
let end = values.last()?;
let rate = (end - start) / 60.0;
if rate >= 0.0 {
Some(rate)
} else {
// this implies there was a counter reset during this window;
// just drop this sample
None
}
}This function takes in a vector of values, finds the first and last values (they are guaranteed to be sorted by time), and computes the rate by dividing it by the time range represented by the aggregate (which we will set to 60 seconds in our query)3.
Now we’re ready to implement our alerting logic:
CREATE VIEW idle_cpu AS
select avg(idle) as idle from (
select irate(value) as idle,
cpu,
hop(interval '5 seconds', interval '60 seconds') as window
from cpu_metrics
where mode = 'idle'
group by cpu, window);This query computes the CPU usage by averaging across all of our CPU cores over a 60 second sliding window, recomputing every 5 seconds. Then we select from that view only those samples that exceed 90% utilization (computed as <10% idle).
Finally we can create our sink that will report our error. We’ll use the webhook sink to integrate with our incident management system. In a real deployment this might be something like the Pagerduty API, but we’re going to go with something a bit simpler: a Slack notification.
After creating a new Slack app with an incoming webhook, we can finish our query:
CREATE TABLE slack (
text TEXT
) WITH (
connector = 'webhook',
endpoint = 'https://hooks.slack.com/services/XXXXXX/XXXXXX/XXXXXX',
headers = 'Content-Type:application/json',
format = 'json'
);
INSERT into slack
SELECT concat('CPU usage is ', round((1.0 - idle) * 100), '%')
FROM idle_cpu
WHERE idle < 0.1;Now we’re ready to run it for real. We’ll preview it one last time (note that previews don’t send data to sinks; all outputs are routed to the results tab), then we can start it.
And after spinning up some high-cpu usage (maybe by running cargo build --release on a Rust project…) we can see our alert in action:

Conclusion
While I don’t recommend replacing Prometheus with Arroyo for your alerting needs today, this example shows how streaming engines like Arroyo can flexibly solve a wide-range of data problems. For example, another Arroyo pipeline could ingest your log data and pull out alert conditions from that.
If you have an interesting use case for Arroyo or streaming data, we’d love to hear about it on Discord.
Full Query
Here’s the final query in full:
create table metrics (
value TEXT,
parsed TEXT generated always as (parse_prom(value))
) WITH (
connector = 'polling_http',
endpoint = 'http://localhost:9100/metrics',
format = 'raw_string',
framing = 'newline',
emit_behavior = 'changed',
poll_interval_ms = '1000'
);
CREATE VIEW cpu_metrics AS
SELECT
extract_json_string(parsed, '$.labels.cpu') AS cpu,
extract_json_string(parsed, '$.labels.mode') AS mode,
CAST(extract_json_string(parsed, '$.value') AS FLOAT) AS value
FROM metrics
WHERE extract_json_string(parsed, '$.name') = 'node_cpu_seconds_total';
CREATE VIEW idle_cpu AS
select avg(idle) as idle from (
select irate(value) as idle,
cpu,
hop(interval '5 seconds', interval '60 seconds') as window
from cpu_metrics
where mode = 'idle'
group by cpu, window);
CREATE TABLE slack (
text TEXT
) WITH (
connector = 'webhook',
endpoint = 'https://hooks.slack.com/services/XXXXXX/XXXXXX/XXXXXX',
headers = 'Content-Type:application/json',
format = 'json'
);
INSERT into slack
SELECT concat('CPU usage is ', round((1.0 - idle) * 100), '%')
FROM idle_cpu
WHERE idle < 0.1;/*
[dependencies]
regex = "1.10.2"
serde_json = "1.0"
*/
fn parse_prom(s: String) -> Option<String> {
use regex::Regex;
use std::collections::HashMap;
// use OnceLock to prevent re-compilation of the regexes on every request
use std::sync::OnceLock;
static METRIC_REGEX: OnceLock<Regex> = OnceLock::new();
let metric_regex = METRIC_REGEX.get_or_init(|| {
Regex::new(r"(?P<metric_name>\w+)\{(?P<labels>[^}]+)\}\s+(?P<metric_value>[\d.]+)").unwrap()
});
static LABEL_REGEX: OnceLock<Regex> = OnceLock::new();
let label_regex = LABEL_REGEX.get_or_init(|| {
regex::Regex::new(r##"(?P<label>[^,]+)="(?P<value>[^"]+)""##).unwrap()
});
// pull out the metric name, labels, and value
let captures = metric_regex.captures(&s)?;
let name = captures.name("metric_name").unwrap().as_str();
let labels = captures.name("labels").unwrap().as_str();
let value = captures.name("metric_value").unwrap().as_str();
// parse out the label key-value pairs
let labels: std::collections::HashMap<String, String> = label_regex.captures_iter(&labels)
.map(|capture| (
capture.name("label").unwrap().as_str().to_string(),
capture.name("value").unwrap().as_str().to_string()
))
.collect();
// return the parsed result as JSON
Some(serde_json::json!({
"name": name,
"labels": labels,
"value": value
}).to_string())
}
fn irate(values: Vec<f32>) -> Option<f32> {
let start = values.first()?;
let end = values.last()?;
let rate = (end - start) / 60.0;
if rate >= 0.0 {
Some(rate)
} else {
// this implies there was a counter reset during this window;
// just drop this sample
None
}
}Footnotes
Currently it’s not possible to return structs from UDFs, so the easiest way to pass multiple pieces of data out of a UDF is to serialize it as JSON ↩
The actual filtering happens on line 11, with the statement
metric_regex.captures(&s)?. The?early returns aOption::Noneif captures returnsNone, because the regex didn’t match. ↩Ideally we would use the actual event time of the data to make this window-size independent, but that isn’t currently possible in Arroyo SQL. ↩